Unless you’ve been living under a rock for the last couple of months, you’re probably aware that governments all over the world have been looking into digital Covid certificates as a way of facilitating freedom of movement and travel for anyone who can prove that they don’t have the cooties.
The EU’s solution is the so-called Digital Covid Certificate (DCC). It is, as the name implies, a personal digital certificate that proves someone has either been vaccinated against Covid, has a recent negative test result, or has recovered from it. The certificate itself is contained in a large QR code, such as this one:

It might look intimidating, but there’s actually nothing mysterious about it. In fact, the whole technical side of the effort is coordinated through a public GitHub organization, which is where you can find all of the technical specs and is also where I got that sample QR image from. This means it’s possible for anyone with a bit of technical know-how to decode these things, which is exactly what we’ll be doing today.
Peeling the onion
Looking at the specs we can see there’s actually two interesting parts. First, there is the Electronic Health Certificate (HCERT), a general-purpose eHealth certificate container. This part specifies the encoding, security, and trust model. Then there is the Digital Covid Certificate (DCC), which is a certificate format containing the actual relevant data regarding someone’s Covid-related claims (e.g. a vaccination). The DCC is just one possible (but currently only) certificate contained within the HCERT container.
The HCERT and DCC use known, open technologies to encode their data. The HCERT (and its contents) is signed by the issuing government to prevent tampering and falsification, but there’s no encryption otherwise. Decoding it is pretty easy, especially with the specs to help us.
Schematically, it looks something like this:
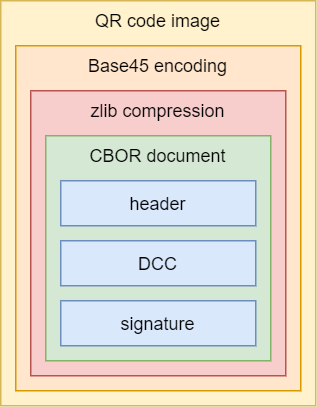
We’ll have to cut through a few layers to get to the DCC, which contains the actual data we’re interested in. Fortunately, my knife for today is Python, which has packages available for literally everything under the sun, including all of this. We’ll only need a few lines of code to get this done. Let’s get going.
First of all, here’s all the imports we’ll need:
from PIL import Image
from pyzbar import pyzbar
from base45 import b45decode
from zlib import decompress
import cbor2
import json
We’ll start by extracting the data from the QR image. In this case, I’m working with the sample QR image shown above.
qr_img = Image.open('042-NL-vaccination.png')
qr_result = pyzbar.decode(qr_img)
qr_data = qr_result[0].data
This gives us the raw data from the QR. For our sample, it looks like this:
HC1:NCF/Y4P8QPO0DO3EIUU*H%34OTC%*8KE9%$VV%P6+JG28O%DSX27VJJJS3-FZ+P84Q88SD3QYI39:0VY9IE1 B87SMUL5ACEKNM2/6GPOV97%8P/8K:2UV$G:FS.5N7+0+ E9.KBV56:RGA0GO69%3M MC-R6UM4PDG5R/3PPHKEN5:5DC24-H4OAHOV0TV2JU6A 9XB298AMMU$S5AYJQXC+IMJE19T55YNQ7G663DZTT$PK9ANS02SD9I66YDEDGQUD+VH CB87DEI5ZF0+8BZHIB9IH/9DPHRU58VT+12YTIIP16YG2Q53912IO7358Z9TJU38MS10N90:D0.CC9K1PHFT08DO6X*PRX12:MRYK.-A -BYR61 57GJ ECN57CVEG*14+B*-LKT5$.AX-EEMS+JF5D3STL7U8GEE/RQDBM758I%IYOJ+9DKX4* A1R5$.U29K.RKYURTHDC692DR1$UOM9V:7EHCT9WYMB+MDZ%FB+FPK288VG-1 9MM7PI3VACP4/T*5TTYVXLC6+DJVLTYE7QII801:PD3
Everything after the “HC1:” header is Base-45 encoded. So, we’ll simply strip the header and throw the rest into our Base-45 decoder:
b45_data = qr_data[4:]
zlib_data = b45decode(b45_data)
That leaves us with the compressed data, which we’ll simply decompress using zlib:
cbor_data = decompress(zlib_data)
Now things get a little bit more interesting. We are now left with a CBOR document (more specifically, a CBOR Web Token, which is a CBOR with a COSE signature) consisting of 4 parts: a header, an unused second header, a payload, and a signature. We can extract those parts as follows:
cbor_data_decoded = cbor2.loads(cbor_data)
(cbor_header, _, cbor_payload, signature) = cbor_data_decoded.value
The header just contains some info on which algorithm was used for the signature and the identifier of the signing key. The signature is, obviously, just the signature. The actual information is contained in the payload, which itself is another CBOR document. We’ll decode it the same way and then (mis)use JSON to pretty-print it for us:
payload = cbor2.loads(cbor_payload)
print(json.dumps(payload, indent=4))
This gives us the following output:
{
"1": "NL",
"4": 1637307800,
"6": 1621755800,
"-260": {
"1": {
"ver": "1.0.0",
"nam": {
"fn": "Achternaam",
"fnt": "ACHTERNAAM",
"gn": "Voornaam",
"gnt": "VOORNAAM"
},
"dob": "1963",
"v": [
{
"tg": "840539006",
"vp": "1119305005",
"mp": "CVnCoV",
"ma": "ORG-100032020",
"dn": 1,
"sd": 6,
"dt": "2021-02-18",
"co": "GR",
"is": "Ministry of Health Welfare and Sport",
"ci": "urn:uvci:01:NL:74827831729545bba1c279f592f2488a"
}
]
}
}
}
And there you have it. That’s a decoded DCC.
Like I said, that was pretty trivial. We haven’t had to jump through any silly hoops or do any weird tweaking or “massaging” of the data. None of the things we’ve done here are specific to the HCERT or DCC either; we’ve literally just decoded a QR image using off-the-shelve, known, proven, and most importantly open technology. I’m pleasantly surprised.
Now, before we try to figure out what each of the fields means, let’s move on to a slightly more interesting working sample…
Decoding a real DCC
As riveting as decoding a sample DCC was, it’s obviously much more interesting when it’s the real deal. And as someone who’s been shanked by the government twice already, I just so happen to have one available. I used the government’s CoronaCheck-app to get my very own QR. The app has some lame “security” where it doesn’t let you take screenshots of it, so I had to use a second camera to take a photo of my phone’s screen, like I’m some kind of boomer. Fortunately, QR codes were literally made to be read from all kinds of weird camera angles, so decoding it from my photo was no issue. Here’s the contents:
{
"1": "NL",
"4": 1630684299,
"6": 1628265099,
"-260": {
"1": {
"ver": "1.3.0",
"dob": "19XX-XX-XX",
"nam": {
"fn": "Wolff",
"fnt": "WOLFF",
"gn": "Bart XXXXX XXXXX",
"gnt": "BART<XXXXX<XXXXX"
},
"v": [
{
"tg": "840539006",
"vp": "1119349007",
"mp": "EU/1/20/1528",
"ma": "ORG-100030215",
"dn": 2,
"sd": 2,
"dt": "2021-XX-XX",
"co": "NL",
"is": "Ministry of Health Welfare and Sport",
"ci": "URN:UCI:01:NL:XXXXXXXXXX#X"
}
]
}
}
}
I’ve redacted a few minor bits of PII, but there’s really no sensitive data in there. Let’s see what it all means.
First up, there’s the issuing country (claim “1”, in my case The Netherlands), and the issue- (claim “6”) and expiry (claim “4”) dates. Apparently this certificate is valid for about a month. The “-260” claim is the actual health certificate, which in turn contains a certificate with claim key “1” that denotes the DCC. These fields are technically all still part of the HCERT. Looking at the contents of the “1” certificate, these are the actual contents of the DCC.
The DCC starts with a schema version string (“ver”), followed by some personal information: date of birth (“dob”) and name (“nam”). Really, the minimal amount of info needed to correlate the DCC to some government-issued travel documents. Next, the DCC can contain information about a Covid vaccination (claim “v”), a negative Covid test result (claim “t”), or recovery from Covid (claim “r”). In my case, my vaccinations are shown, with the following info:
- “tg” denotes the disease that was targeted. As we can look up, the value “840539006” corresponds to Covid-19.
- “vp” denotes the type of vaccine. As we can look up, the value “1119349007” indicates that an mRNA vaccine for SARS-CoV-2 was used.
- “mp” denotes the vaccine product. As we can look up, the value “EU/1/20/1528” corresponds to Biontech’s Comirnaty vaccine.
- “ma” denotes the vaccine manufacturer. As we can look up, the value “ORG-100030215” corresponds to Biontech.
- “dn” denotes the n-th vaccine dose that was received. In this case, it shows I’ve received my second dose.
- “sd” denotes the total number of doses that the vaccine protocol requires. In this case, the Comirnaty vaccine requires two doses as shown here.
- “dt” denotes the date on which the vaccine dose was received.
- “co” denotes the country in which the vaccine dose was received.
- “is” denotes the issuer of the DCC. In this case, the Dutch Ministerie van Volksgezondheid.
- “ci” denotes the unique identifier of the DCC.
Overall, there’s not too much “exciting” data in there. In fact, there’s pretty much just the minimal amount of information needed for doing what it’s supposed to do. Apparently some people are worried about this thing being a leaky cauldron of personal and medical details, but that’s really not the case. And you don’t have to take my word for it; as I’ve shown here it’s actually very simple to check the contents of your own QR code.
References
HCERT specification: https://github.com/ehn-dcc-development/hcert-spec
DCC schema specification: https://github.com/ehn-dcc-development/ehn-dcc-schema
Base-45 specification: http://datatracker.ietf.org/doc/html/draft-faltstrom-base45-07
CBOR specification: https://datatracker.ietf.org/doc/html/rfc7049
COSE specification: http://datatracker.ietf.org/doc/html/rfc8152
CWT specification: http://datatracker.ietf.org/doc/html/rfc8392